Original Paper : OpenVLA: An Open-Source Vision-Language-Action Model
OpenSource repo : OpenVLA
Abstract
OpenVLA provides an open-source outpeforming current SOTA models.
Supporting fine-tunning notebooks with LORA adaption.
Model architecture
Backbone
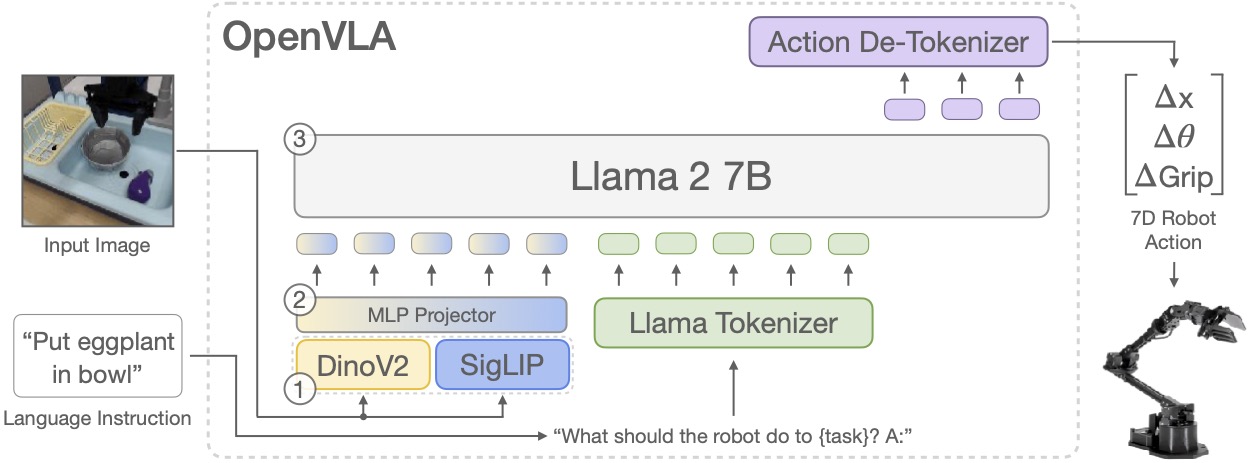
기본적인 VLM 기반으로, vision encoder 2개를 concat해서 Prismatic-7B VLM에 넣으면 action token이 나오는 형식.
Pretrained-VLM(Karamcheti) backbone + Open-X 970K dataset
Karamcheti가 Llama2-7B + DINOv2 + SigLIP를 합쳐서 쓰는게 좋다는 연구결과 (DINOv2 : helpful for improved spatial reasoning)
해당 구조가 가지는 이점
- Having performance aligned with large, Internet-scal vision-language dataset
- Using generic architecture, reducing efforts for code modification and scalable training
- Having generality and open-source for rapidly improving VLM, VLA fields
Actions Tokens
각 action은 256bin으로 이산화 됨.
각 훈련 데이터의 1th quantile와 99th quantile을 기준으로 균등하게 나눔.
-> 이렇게 함으로써 outlier에 대해서 로봇의 불안정성을 완화시킬 수 있음.
Llama2 의 100 special token으로는 action token 256개를 관리할 수 없어서, 가장 사용되지 않는 token을 할당해서 사용한다고 한다.
직접 모델 돌려봐야 확실하게 직관이 설 듯.
원래 있던 단어에 대한 능력은 가지고 있는 상태에서 256개만 확보해서 fine tunning을 해서 llm이 햇갈리지 않게 하는거, 원래 있던 단어 토큰을 action token에게 전달할 bin으로 사용하면 llm 내부에 학습된 많은 정보들이 햇갈리게 됨.
Traning
next-token prediction , end-to-end training
- no freezing
- balanced mix of dataset(embodiments, tasks, and scenes)
- input 224x224px
- 27 epochs
- lr 2e-5
Results
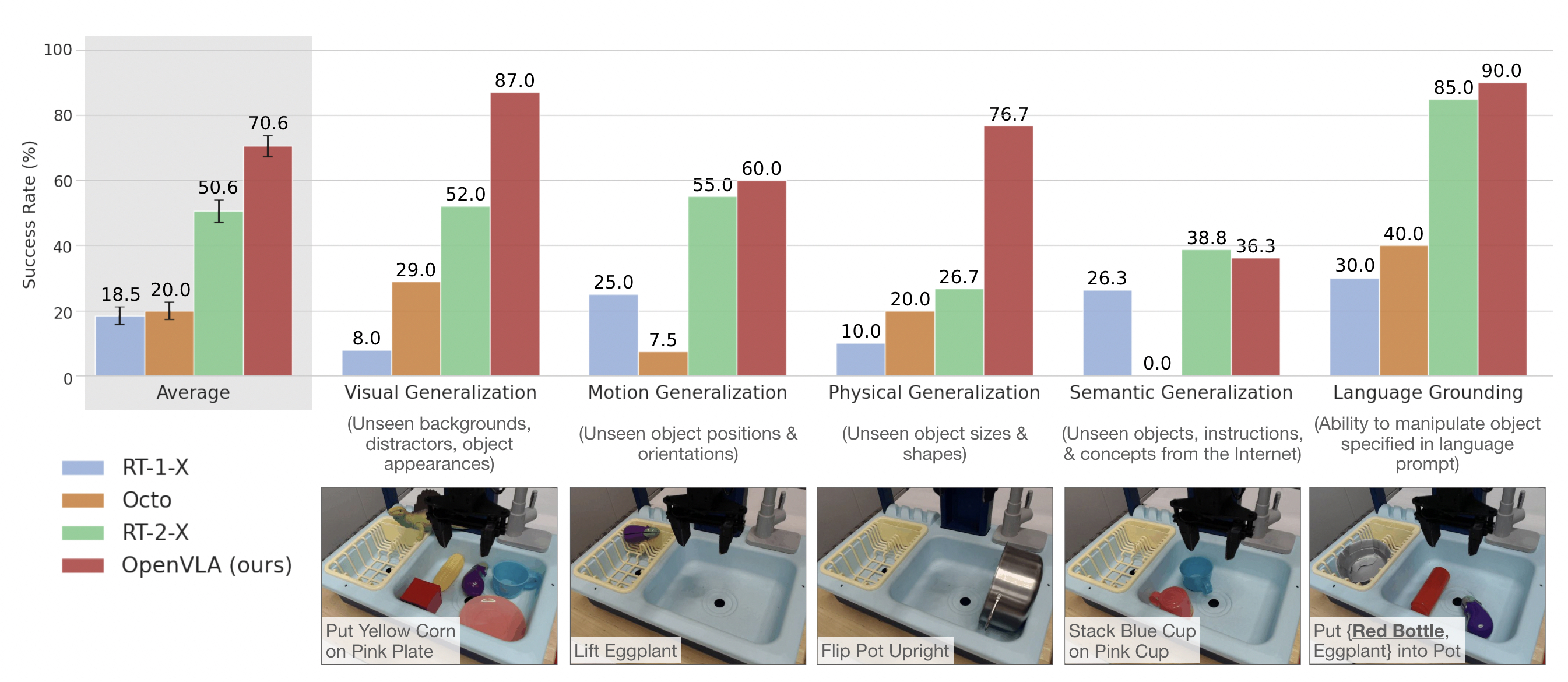
BridgeData V2 WidowX robot evaluation tasks and results
기존 SOTA 모델인 RT-2-X(55B)보다 16.5% 높은 성공률을 기록하며 압도적인 범용 제어 및 일반화 성능을 입증했습니다.
Adapting to new robot setups
단 10~150개의 소량 데모 데이터만으로도 새로운 로봇 환경에 빠르게 적응하며, 특히 언어 이해가 필요한 복잡한 다중 작업에서 Diffusion Policy와 같은 기존 방식보다 뛰어난 효율성을 보여주었습니다.
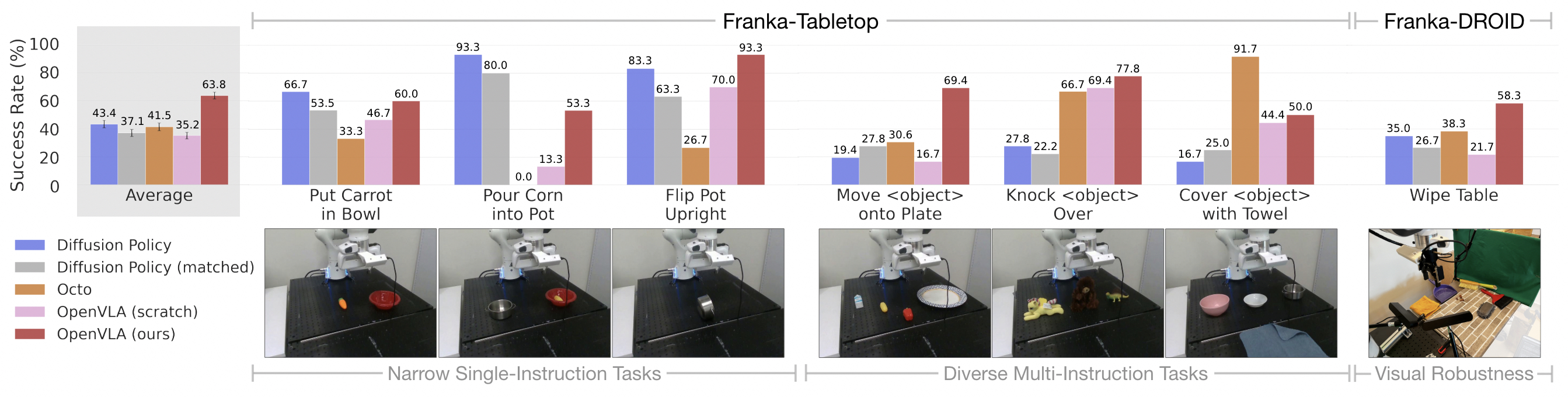
For narrower but highly dexterous tasks, Diffusion Policy still shows smoother and more precise trajectories; incorporating action chunking and temporal smoothing, as implemented in Diffusion Policy, may help OpenVLA attain the same level of dexterity and may be a promising direction for future work (see Section 6 for a detailed discussion of current limitations).
Parameter-Efficient Fine-Tuning
LoRA, rank=32 is the best.
Limitations
- Only supports single-image observations.
- improving the inference speed throughput of OpenVLA is critical for realtime high-frequency control setups.
- NOT YET very high reliability, cause it achieving <90% success rate on most tasks.
- Finally, due to compute limitations, many VLA design questions remain underexplored:
Ablation Study
D1. OpenX Training Data Ablation Experiments
OpenX를 학습하지 않고, BridgeData V2만 학습한 OpenVLA-Bridge 와 비교를 했다.
처참하게 75%와 45%로 bridge의 성능이 나오지 않았다.
OpenX training mixture is essential for unlocking improved generalization capabilities in the OpenVLA model.
D2. Dual vs. Single Vision Encoder Experiments
ablating Dino V2 vision encoder.
OpenX full dataset으로 학습하면 시간 오래걸리니까, ablation study에서는 BridgeData V2만 학습한 모델(OpenVLA-Bridge)로 비교.
- OpenVLA-Bridge : w DinoV2
- OpenVLA-Bridge-SigLIP : wo DinoV2
Only 5% degradation, not quite signinficant.
The low-level spatial features represented in DinoV2 appear to aid generalization in only some cases.
D3. Fine-tunned vs Frozen Vision Encoder Experiments
SigLIP ViT-SO 224px and LLaVa v1.5 7B is the pretrained one.
Fine-tuning the vision encoder leads to significantly higher success rates across various tasks.
Qualitively하게는 frozen encoder를 사용했을 때, robot이 unsable하게 움직였다고 한다.
D4. Additional Quantized Inference Experiments: Disentangling Policy Performance and Model Inference Speed
8-bit quantization has lower performance than even 4-bit quantization.
They hypothesized that the reduction in performance was caused by lower model inference speed.
So, eveluating with blocking control.
Meaning every action is fully executed before the next action is taken.
| Precision | Non-Blocking | Blocking |
|---|---|---|
| bfloat16 | 71.3 ±4.8% | 70.0 ±5.1% |
| int8 | 58.1 ±5.1% | 74.4 ±4.9% |
| int4 | 71.9 ±4.7% | 68.8 ±5.2% |
Learned
bf16이 8-bit보다 빠른 이유?
Figure6를 보면, RTX4090 단일 GPU에서
| precision | Actions/sec |
|---|---|
| bfloat16 | 6.1 |
| int8 | 2 |
| int4 | 6 |
사실 GPU Tensor Core spec을 보면, int8이 bf16보다 빠르지만, 양자화 과정에서 오버헤드가 발생해서 하드웨어 이점을 모두 상쇄한다.
| rtx 4090 | |
|---|---|
| Peak BF16 Tensor TFLOPS | 165.2/330.42 |
| Peak TF32 Tensor TFLOPS | 82.6/165.22 |
| Peak INT8 Tensor TOPS | 660.6/1321.22 |
| Peak INT4 Tensor TOPS | 1321.2/2642.42 |
int4는 quantization overhead가 없나?
결국 또 memory-bound issue로 귀결된다.
int4로 가면서 양자화 오버헤드를 넘을 만큼의 memory 이점이 생긴다는 거다.
그러면 근데 왜 int4쓰나, 그냥 bf16으로 정확도랑 속도 둘 다 잡지? 단 하나의 이점은 메모리니까, 그러면 차라리 모델 사이즈를 키우고 int4 quantization을 사용해서 성능 이점을 가져가는 편이 좋을듯하다.
뭔가 Cuda TensorRT나 그런 SW 최적화가 부족한 결과라고 보인다.
아? 논문에 써있었음.
Further speed-ups are possible with modern LLM inference frameworks like TensorRT-LLM. (Figure6)
Diffusion 기반 Action model의 강점
정확도나 action의 부드러움 정도가 놀라움.
논문에서 Narrow Tasks에 대해서는 굉장히 높은 정확도를 보여줌.
아지만 distractors나 novel object와 같은 generalization이 필요한 상황에서의 많은 약점을 가짐.
결과적으로 단 한가지 task를 제외한 평균적인 성능은 OpenVLA가 우위를 가짐.