Original Paper : VLA-0: Building State-of-the-Art VLAs with Zero Modification
OpenSource repo : https://vla0.github.io/
Introductions
1. Discrete Token VLA (RT-2 / Open-VLA)
Key architecture : Robot actions, originally continuous, are discretized into bins; each bin is then assigned a token from the VLM vocabulary, using either new or infrequent tokens
Mostly made by google, it has two limitations.
- As it restrict the actions into discrete bins, fine-grained control is limited. (resolution of actions)
- It compromises pretrained language understanding of the VLM by repurposing its vocabulary for actions
2. Generative Action Head VLAs
Key architecture : The VLM is fine-tuned to predict a latent vector, which is then decoded into actions using a generative model such as a diffusion process or flow matching.
The primary drawback is,
This often leads to a decline in the language understanding and grounding capabilities of the underlying VLM.
3. Custom Architecture VLAs
It contains architectural modifications or custom tokenizers tailored to action prediction.
But, significant architectural changes, additional parameters, or custom training pipelines.
2. Related Works
The key to our success lies in a carefully designed training and inference recipe, including action token masking and prediction ensembling, a critical component not explored in LLARVA(2-stage text based action prediction).
3. Methods
VLM (Vision-Languge-Mdoel)
- Pre-trained Encoder -> Projecting patches of Image into LLM’s embedding space.
- LLM tokenizer -> Embedding input text.
Backbone : Qwen-VL-2.5-3B model
For reproducibility, compute efficiency, competitive performance for its model size.
VLA-0
VLA-0 preserves the integrity of the underlying VLM : it does not introduce new tokens, alter the existing vocabulary, or add any new neural network layers.
However, achieving this performance relies on a careful recipe.
Inputs
System Prompt, Images, and a Task Instruction.
- System Prompts :
Analyze the input image and predict robot actions for the next H timesteps. Each action has D dimensions. Output a single sequence of H× Dintegers (0 - B each), representing the H timesteps sequentially. Provide only space-separated numbers. Nothing else.
- Images :
Simulation : (Third person view + wrist view) like basemodel
Real test : right / left image
- Task Instruction :
e.g. “put the banana on the plate.”
Action Decoding
As VLA-0 returns the text generated action.
To simplify this task, we ask the VLM to output actions as integers.
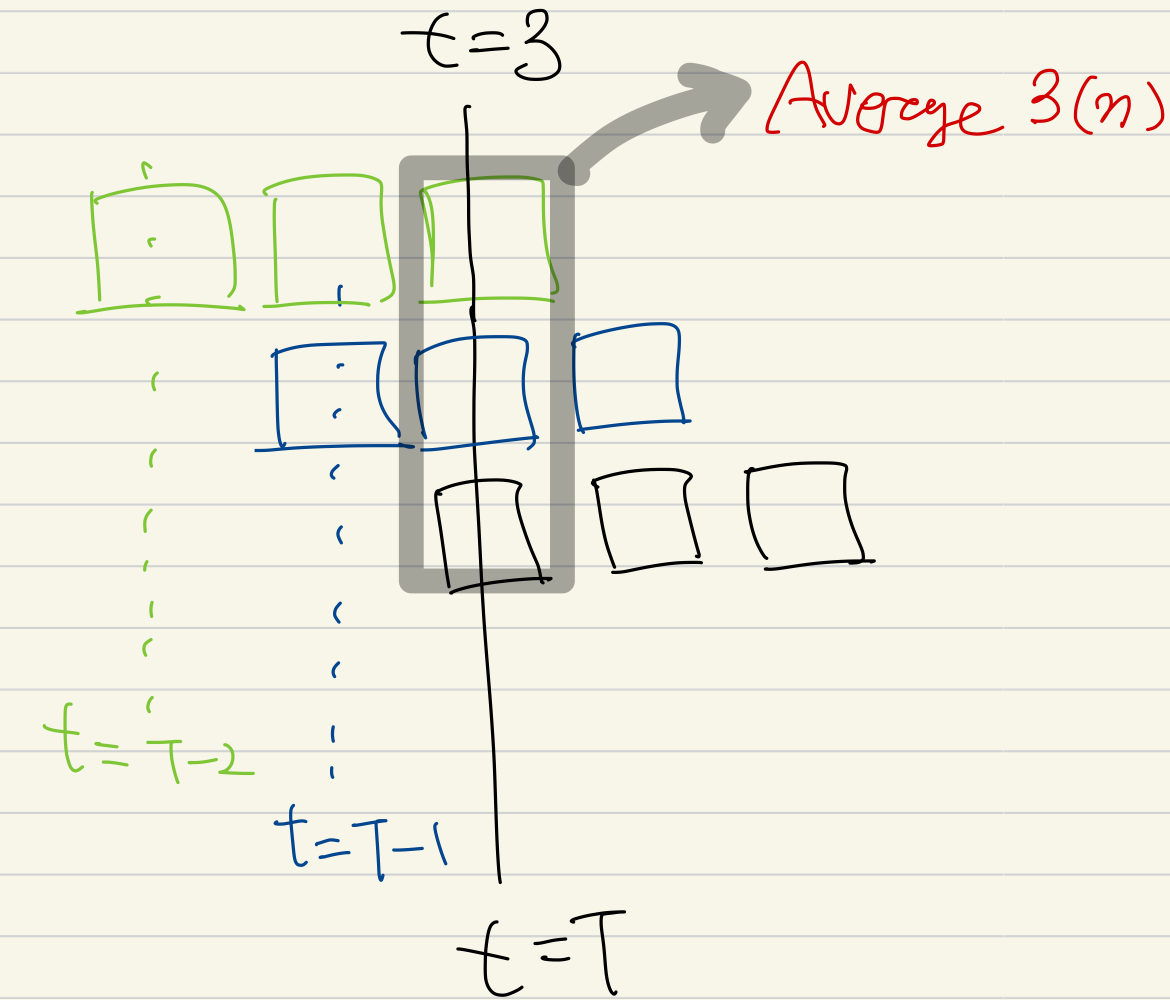
Ensemble Prediction
At each inference step, the VLM predicts a sequence of nfuture actions.
We average these npredictions to produce the final, more stable action at time step t.
Masked Action Augmentation (training augmentation)
During training, we randomly mask out characters in the target action string.
This procedure forces the VLM to reason about the action based on the visual observation and instruction, rather than simply relying on auto-completing a numerical sequence it has started to generate.
4. EXPERIMENTS
Setup
Tasks (World)
- reorienting ablock
- pushing an apple
- picking and placing a banana
- picking and placing a cupcake.
For each task, we collect 100 demonstrations for training.
Tasks (Simulation)
LIBERO consists of four suites: Spatial, Object, Goal, and Long.
Each suite contains 10 tasks, and each task is tested over 50 episodes.
Baselines
See the Below table.
Tables
| Models | Large-scale pre-train |
VLA Type | Spatial | Object | Goal | Long | Avg. | Avg. rank |
|---|---|---|---|---|---|---|---|---|
| Diffusion Policy [4], [11] | ✗ | N/A | 78.3 | 92.5 | 68.3 | 50.5 | 72.4 | 6.5 |
| π0-FAST (Paligemma) [2], [19] | ✗ | Custom | 87.0 | 63.0 | 89.0 | 48.0 | 71.8 | 6.0 |
| SmolVLA (0.24B) [19] | ✗ | Gen Head | 87.0 | 93.0 | 88.0 | 63.0 | 82.8 | 5.3 |
| SmolVLA (2.25B) [19] | ✗ | Gen Head | 93.0 | 94.0 | 91.0 | 77.0 | 88.8 | 4.0 |
| OpenVLA-OFT [10] | ✗ | Custom | 94.3 | 95.2 | 91.7 | 86.5 | 91.9 | 2.8 |
| π0.5 - KI [5] | ✗ | Gen Head | 96.6 | 97.2 | 94.6 | 85.8 | 93.3 | 2.3 |
| VLA-0 (Ours) | ✗ | Simple | 97.0 | 97.8 | 96.2 | 87.6 | 94.7 | 1.0 |
| Octo [21] | ✓ | Gen Head | 78.9 | 85.7 | 84.6 | 51.1 | 75.1 | 8.8 |
| OpenVLA [11] | ✓ | Dis. Tok. | 84.7 | 88.4 | 79.2 | 53.7 | 76.5 | 8.0 |
| π0-FAST [16] | ✓ | Custom | 90.0 | 86.0 | 95.0 | 73.0 | 86.0 | 6.5 |
| Molmo Act [12] | ✓ | Dis. Tok. | 87.0 | 95.4 | 87.6 | 77.2 | 86.8 | 6.5 |
| GR00T-N1 [1] | ✓ | Gen Head | 94.4 | 97.6 | 93.0 | 90.6 | 93.9 | 4.5 |
| π0 [2] | ✓ | Gen Head | 96.8 | 98.8 | 95.8 | 85.2 | 94.2 | 3.3 |
| π0.5 - KI [5] | ✓ | Gen Head | 98.0 | 97.8 | 95.6 | 85.8 | 94.3 | 3.0 |
| OpenVLA-OFT [10] | ✓ | Custom | 97.6 | 98.4 | 97.9 | 94.5 | 97.1 | 1.5 |
| VLA-0 (Ours) | ✗ | Simple | 97.0 | 97.8 | 96.2 | 87.6 | 94.7 | 2.8 |
Results
At simulation (LIBERO),
- No large-scale pre-train : outperforming the second best method by 1.4 points on average.
- With large-scale pre-train : Overall, it gets the second best average rank 2.8, trailing only OpenVLA-OFT [10] (average rank 1.5), a custom VLA model.
At real-world,
- We compare with SmolVLA [19], a strong baseline that was specifically trained on the large-scale SO-100 dataset and has been shown to outperform popular methods like π0 [2] and ACT [23] on this platform.
Ablation studies
| Row ID | Ensemble Act. | Masked Act. Aug. | Tiled Img. | Act. Res. | Avg. Succ. | Δ perf. |
|---|---|---|---|---|---|---|
| 0 | ✓ | ✓ | ✓ | 1000 | 94.7 | 0.0 |
| 1 | ✗ | ✓ | ✓ | 1000 | 92.0 | -2.0 |
| 2 | ✓ | ✗ | ✓ | 1000 | 93.5 | -1.2 |
| 3 | ✓ | ✓ | ✓ | 4000 | 94.2 | -0.5 |
| 4 | ✓ | ✓ | ✓ | 250 | 93.2 | -1.5 |
| 5 | ✓ | ✓ | ✗ | 1000 | 94.5 | -0.2 |
5. Conculsion
The key strength of the research is zero-modification of VLM.
Without adding extra action tokens or encoder, adopting carefully designed training and inference recipe can achieve SOTA when compared with samely not Largely pre-trained VLAs.
Learned
Action Vectors
- (dx,dy,dz)
- (droll, dpitch, dyaw)
- (gripper)

Does VLA-0 has general task model?
YES?
Personal Thoughts
결국 모든 VLA들은 현재 VLM의 이미지 기반 상황인식과 + text input을 동시에 받을 수 있는 지점을 이용한다.
VLM을 굳이 채택하는 이유는 결국 로봇의 상황판단은 물리세계에 대한 이해를 의미하고, 그 지점에서대규모 인터넷 자료를 학습한 pre-trained VLM의 이점을 사용하는 것이다.